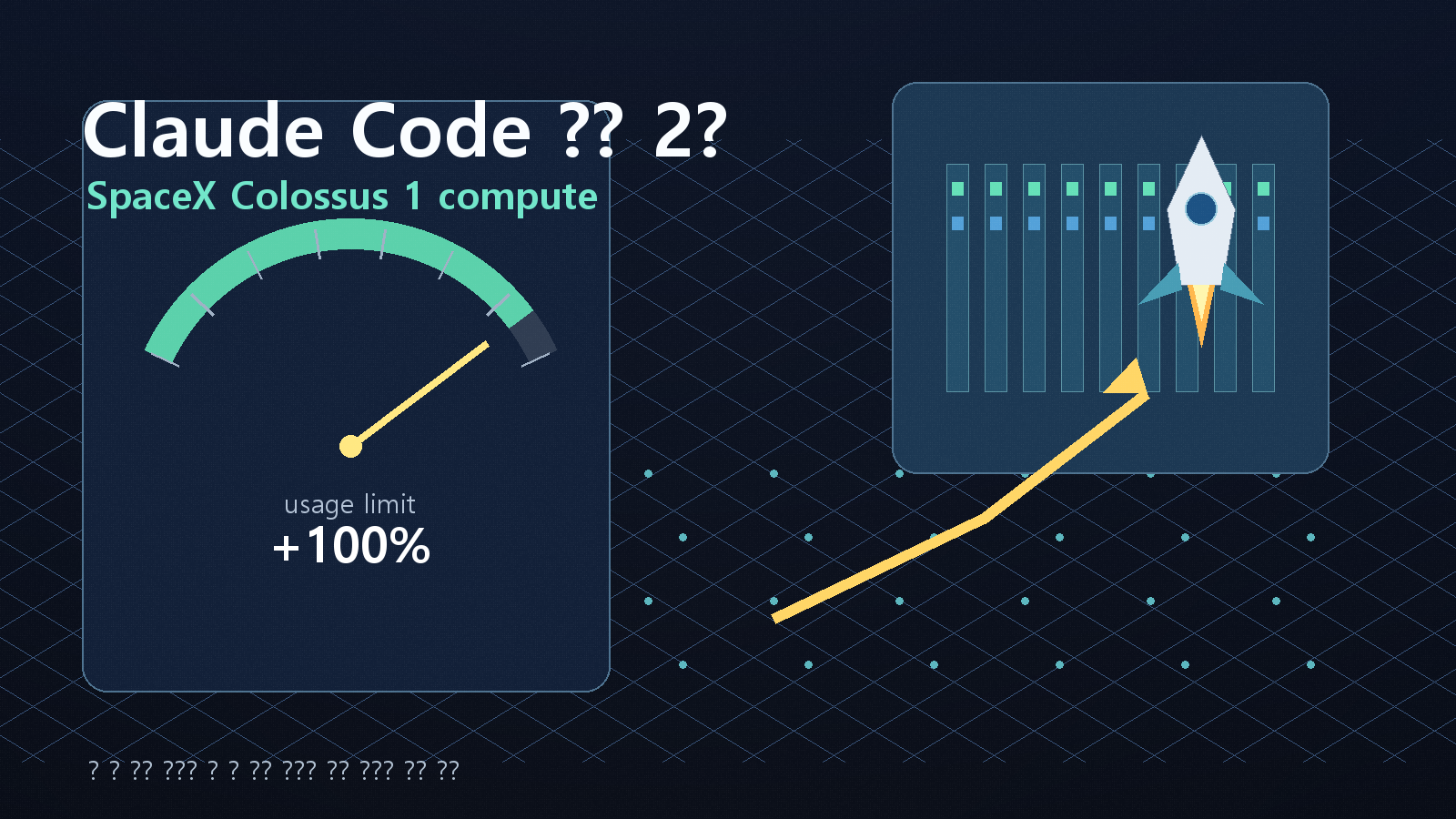
Anthropic이 Claude 사용 한도 확대와 SpaceX compute 확보를 함께 내놨다. 2026년 5월 6일 xAI는 SpaceXAI가 Anthropic에 Colossus 1 접근을 제공하는 계약을 맺었다고 발표했고, Axios는 Anthropic 측 설명을 인용해 Claude Code와 Claude API 한도 확대가 이 compute 확보와 연결된다고 보도했다.
이번 뉴스의 핵심은 새 Claude 모델이 아니다. Claude를 더 오래, 더 안정적으로, 더 높은 rate limit 안에서 쓰게 만들기 위한 인프라 확장이다. AI 경쟁이 모델 성능만의 싸움이 아니라 GPU, 전력, 데이터센터, 공급 안정성의 싸움으로 더 직접적으로 이동하고 있다는 신호다.
한눈에 보기
- 발표 내용: Anthropic이 SpaceX의 Colossus 1 compute capacity를 확보했다.
- 규모: xAI 발표 기준 Colossus 1은 220,000개 이상의 NVIDIA GPU를 포함한다.
- 사용자 변화: Claude Code의 5시간 rate limit 확대, Pro/Max 피크 시간대 제한 축소 제거, Claude Opus API rate limit 상향이 함께 언급됐다.
- 주의할 점: 실제 latency, 응답 속도, 계정별 정확한 API 한도 체감은 별도 확인이 필요하다.
- 한 줄 결론: 이번 발표의 주인공은 새 기능이 아니라 Claude 수요를 버티기 위한 compute 확보였다.
무엇이 발표됐나
xAI의 공식 발표에 따르면 SpaceXAI는 Anthropic에 Colossus 1 접근을 제공하는 계약을 체결했다. xAI는 Colossus 1이 H100, H200, 차세대 GB200 accelerator를 포함한 220,000개 이상의 NVIDIA GPU로 구성되어 있다고 설명했다.
Axios는 Anthropic이 SpaceX compute capacity에 접근하는 계약을 맺었고, 이 계약이 급증하는 Claude 수요를 감당하는 데 도움이 될 수 있다고 보도했다. Axios 보도 기준으로 Anthropic은 Colossus 1 데이터센터의 전체 capacity를 사용하기로 했고, 한 달 안에 300MW 이상의 신규 capacity와 220,000개 이상의 NVIDIA GPU에 접근하게 된다고 설명했다.
사용자 입장에서 바로 보이는 변화는 Claude Code와 Claude API 한도다. Axios는 Anthropic이 Pro, Max, Team, seat-based Enterprise 플랜의 Claude Code 5시간 rate limit을 올리고, Pro와 Max 사용자의 피크 시간대 한도 축소를 제거하며, Opus 모델 API rate limit도 올린다고 전했다.
핵심 변화 3가지
1. Claude Code 한도 확대
Claude Code를 장시간 쓰는 사용자에게 가장 직접적인 변화는 5시간 rate limit 확대다. 코딩 에이전트는 긴 작업 중간에 컨텍스트를 계속 유지하고 파일을 읽고 수정하며 테스트를 반복한다. 이 흐름에서 한도에 걸리면 생산성이 바로 끊긴다.
따라서 이번 변화는 단순히 "메시지를 더 보낸다"보다 실제 개발 세션을 더 오래 유지할 수 있느냐의 문제에 가깝다. Claude Code를 업무 도구로 쓰는 팀에는 체감 가능성이 있다.
2. Pro와 Max의 피크 시간대 제한 완화
Pro와 Max 계정에서 Claude Code의 피크 시간대 한도 축소가 제거됐다는 점도 중요하다. 사용량이 몰리는 시간대에 한도가 더 빠르게 줄어드는 구조는 예측 가능성을 낮춘다. 이번 변화는 적어도 paid user 경험을 더 안정적으로 만들려는 조치다.
다만 이것이 모든 지역과 모든 시간대에서 동일한 응답 속도 개선을 보장한다는 뜻은 아니다. 발표와 보도에서 확인되는 것은 capacity와 usage limit 변화이지, 세부 latency SLA는 아니다.
3. Opus API rate limit 상향
개발자와 제품팀에는 Opus API rate limit 상향이 중요하다. 고성능 모델을 실제 서비스에 붙이면 병목은 모델 품질만이 아니라 requests per minute, tokens per minute, burst 처리, 비용 관리로 옮겨간다.
Anthropic이 Opus API 한도를 올렸다는 것은 제품 통합 관점에서 의미가 있다. 다만 계정 tier별 구체 수치와 실제 적용 범위는 Anthropic Console과 공식 문서를 기준으로 확인해야 한다.
왜 SpaceX compute가 중요해졌나
Claude 같은 frontier AI 서비스는 수요가 늘수록 단순 서버 증설로 해결되지 않는다. 고성능 GPU, 전력, 냉각, 네트워크, 지역별 capacity, 안정적인 운영 체계가 같이 필요하다. 사용자 입장에서는 "답변이 잘 나온다"가 중요하지만, 공급자 입장에서는 그 답변을 얼마나 많이, 얼마나 안정적으로 제공할 수 있는지가 핵심이다.
Anthropic은 이미 여러 compute deal을 공개해왔다. Amazon과의 대규모 compute 협력, Google Cloud TPU 확대, Microsoft와 NVIDIA를 통한 Azure capacity, Fluidstack과의 미국 AI 인프라 투자 등이 이 흐름에 있다. 이번 SpaceX 계약은 그 compute 확보 전략에 Colossus 1을 추가한 것이다.
여기서 xAI와 Anthropic이 경쟁사라는 점도 흥미롭다. xAI의 Grok과 Anthropic의 Claude는 같은 시장에서 경쟁하지만, compute capacity는 별도의 산업 자산으로 거래될 수 있다. AI 시장이 모델 회사, 클라우드 회사, 데이터센터 운영자, 전력 인프라가 얽힌 공급망 경쟁으로 변하고 있다는 뜻이다.
과하게 해석하면 안 되는 부분
이번 발표에는 orbital AI compute 이야기도 포함되어 있다. xAI는 Anthropic이 SpaceX와 여러 GW 규모의 orbital AI compute capacity 개발에 관심을 표명했다고 밝혔다. 이 표현은 흥미롭지만, 당장 운영 중인 제품이나 확정된 인프라로 보면 안 된다.
현재 확인 가능한 핵심은 Colossus 1 접근과 Claude usage limit 개선이다. 우주 기반 AI compute는 장기 구상이나 탐색적 협력에 가깝게 보는 것이 맞다.
또 "220,000개 GPU"라는 숫자도 곧바로 사용자 경험 개선 폭으로 환산되지는 않는다. 모델 종류, 추론 최적화, 트래픽 패턴, 지역별 routing, 계정별 정책에 따라 체감은 달라질 수 있다.
사용자와 제품팀에게 주는 의미
일반 사용자에게는 새 기능보다 사용 가능량과 안정성이 중요하다. Claude Pro와 Max를 자주 쓰는 사용자는 한도 체감이 달라질 수 있다. 특히 Claude Code를 쓰는 개발자는 긴 작업 중간에 멈추는 빈도가 줄어드는지가 관찰 포인트다.
개발자에게는 API rate limit이 더 중요하다. 제품에 Claude Opus를 붙이는 팀은 처리량이 늘어나면 더 많은 요청을 안정적으로 보낼 수 있지만, 비용과 장애 대응도 같이 관리해야 한다. 한도가 올라가면 편해지는 동시에 과금 리스크도 커진다.
창업자 관점에서는 AI 제품의 경쟁력이 모델 선택만으로 결정되지 않는다는 점을 다시 보여준다. 실제 서비스에서는 "어떤 모델을 쓰느냐"만큼 "수요가 몰릴 때 안정적으로 공급받을 수 있느냐"가 중요하다.
결론
Anthropic의 SpaceX compute 확보는 Claude 생태계에서 꽤 실무적인 뉴스다. 새 모델의 성능표보다 덜 화려하지만, 실제 사용자와 개발자에게는 한도와 capacity가 더 직접적인 문제일 때가 많다.
이번 발표는 Claude 경쟁력이 모델 품질만이 아니라 인프라 확보 능력에도 걸려 있다는 점을 분명히 보여준다. 앞으로 AI 서비스 평가는 "모델이 얼마나 좋은가"와 함께 "그 모델을 얼마나 안정적으로 공급할 수 있는가"까지 봐야 한다.
한 줄 평: "이번 발표의 진짜 주인공은 새 Claude 기능이 아니라, Claude를 더 많이 돌리기 위한 compute 확보였다."