Mistral OCR 4 공개: 문서 AI가 단순 OCR을 넘어섰다
Mistral OCR 4 공개, 핵심은 문서를 텍스트가 아니라 구조와 근거가 있는 데이터로 바꾸는 변화였다
한눈에 보기
- 발표 내용: Mistral AI가 문서 인식용 모델 Mistral OCR 4를 공개했다.
- 핵심 변화: 추출 텍스트와 함께 바운딩 박스, 블록 분류, 신뢰도 점수를 제공한다.
- 한 줄 결론: RAG와 사내 문서 검색에서 "무슨 내용인가"뿐 아니라 "어디서 나온 내용인가"까지 다루려는 업데이트다.

이번 발표, 뭐가 나왔나
Mistral AI가 2026년 6월 23일 공식 블로그를 통해 Mistral OCR 4를 공개했다. 이름만 보면 OCR 성능 개선처럼 보이지만, 핵심은 문서를 단순 텍스트가 아니라 검색과 RAG에 넣기 쉬운 구조 데이터로 바꾸는 쪽에 가깝다. 공식 발표에 따르면 OCR 4는 170개 언어와 10개 언어 그룹을 지원하고, PDF, DOC, PPT, OpenDocument 같은 기업용 문서 형식을 처리한다.
핵심 변화 3가지
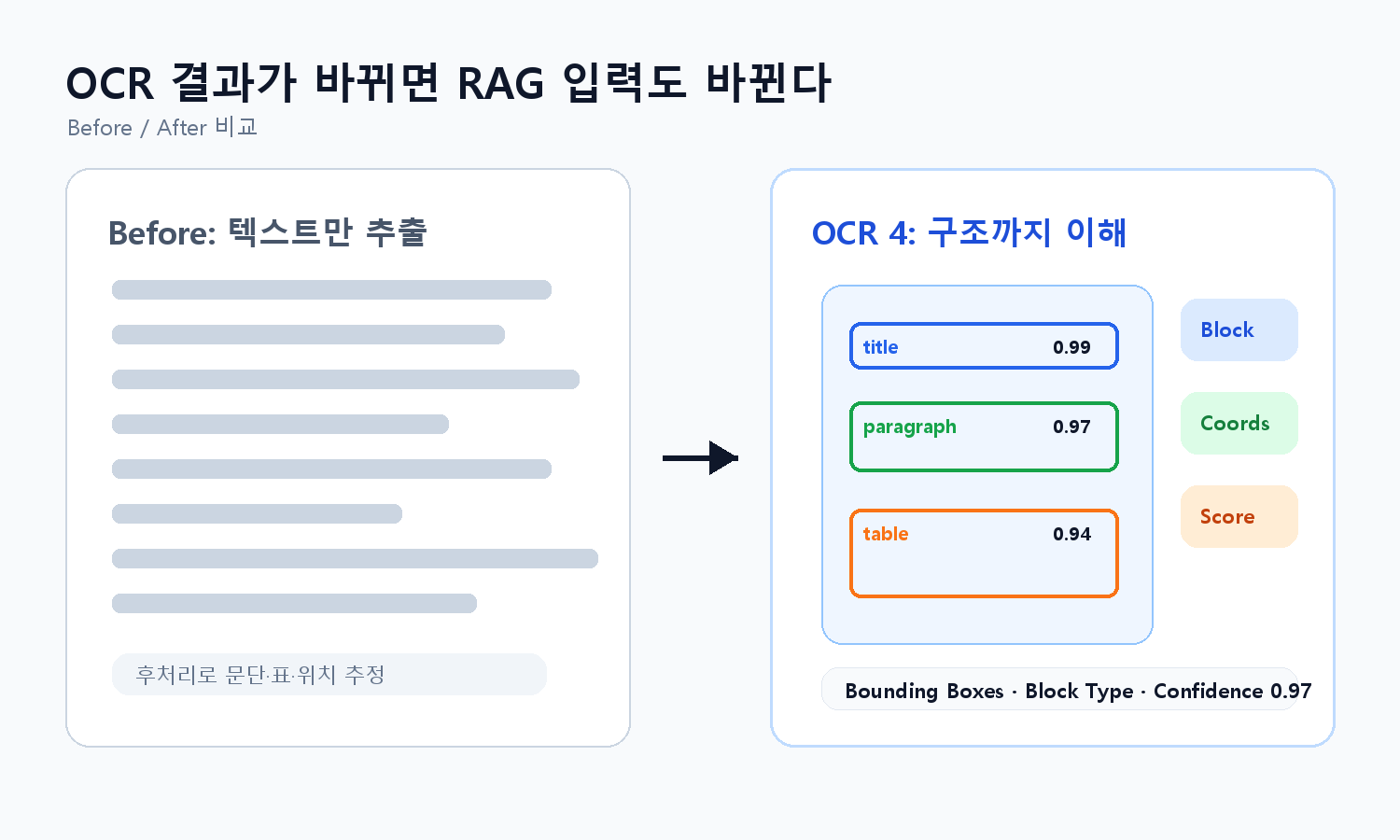
1. 텍스트와 함께 위치 정보가 나온다
OCR 4는 추출된 텍스트만 내보내는 데서 멈추지 않고, 바운딩 박스와 블록 정보를 함께 제공한다. 문서의 어느 영역에서 해당 문장이 나왔는지 알 수 있다는 뜻이다.
이전 방식에서는 OCR 이후에 문단을 다시 나누고, 표나 제목을 추정하고, 원문 위치를 맞추는 후처리가 필요했다. OCR 4가 이 정보를 모델 출력 단계에서 같이 제공하면, 문서 검색이나 감사 로그를 만들 때 손이 덜 간다.
2. 블록 분류와 신뢰도 점수가 붙는다
Mistral 문서에 따르면 OCR 4에서는 include_blocks 옵션으로 페이지별 블록 배열을 받을 수 있고, confidence_scores_granularity 옵션으로 페이지 단위나 단어 단위 신뢰도 점수를 받을 수 있다. 사용자 입장에서는 이 부분이 먼저 보인다. "읽었다"가 아니라 "어느 정도 믿어도 되는지"까지 표시할 수 있기 때문이다.
실무에서는 신뢰도가 낮은 영역만 따로 검수하거나, 민감한 문서에서 확실하지 않은 구간을 자동 표시하는 식으로 이어질 수 있다. 문서 자동화에서 꽤 현실적인 변화다.
3. RAG 입력 파이프라인을 겨냥했다
Mistral은 OCR 4를 기업 검색, RAG, 도메인 특화 검색 파이프라인의 ingestion component로 설명한다. 쉽게 말하면 문서를 AI가 읽기 좋은 형태로 바꿔주는 앞단 부품이라는 의미다.
RAG 품질은 모델만 좋아진다고 해결되지 않는다. 문서를 잘게 나누는 방식, 표와 이미지 설명을 보존하는 방식, 원문 출처를 연결하는 방식이 같이 중요하다. OCR 4는 이 앞단 품질을 올리는 쪽에 초점을 맞춘 업데이트로 볼 수 있다.
그래서 실제로 뭐가 달라지나
일반 사용자 기준
스캔 PDF나 복잡한 문서에서 검색 결과가 좀 더 설명 가능해질 수 있다. 단순히 문장만 찾는 것이 아니라, 그 문장이 문서의 어느 위치에 있었는지까지 연결할 수 있기 때문이다. 다만 한국어 실문서, 표가 많은 보고서, 흐린 스캔 문서에서 어느 정도 안정적인지는 아직 확인 필요다.
개발자 기준
개발자에게는 OCR 결과를 후처리하는 방식이 달라진다. 텍스트, 좌표, 블록 타입, 신뢰도 점수를 함께 받으면 문서 chunking, 인덱싱, 검수 UI를 더 명확하게 설계할 수 있다. 가격은 공식 발표 기준 OCR 4 API가 1,000페이지당 4달러, Batch API가 1,000페이지당 2달러, Document AI가 1,000페이지당 5달러다.
창업자/업무 활용 기준
문서 AI 제품을 만드는 팀이라면 OCR 4를 "OCR 엔진"보다 "문서 입력 품질을 다루는 인프라"로 보는 편이 맞다. 고객사 문서를 외부 API로 보내기 어려운 경우에는 단일 컨테이너 기반 self-hosted deployment 가능성도 검토 포인트가 된다. 단, self-hosting 조건과 실제 운영 요구사항은 아직 확인 필요다.
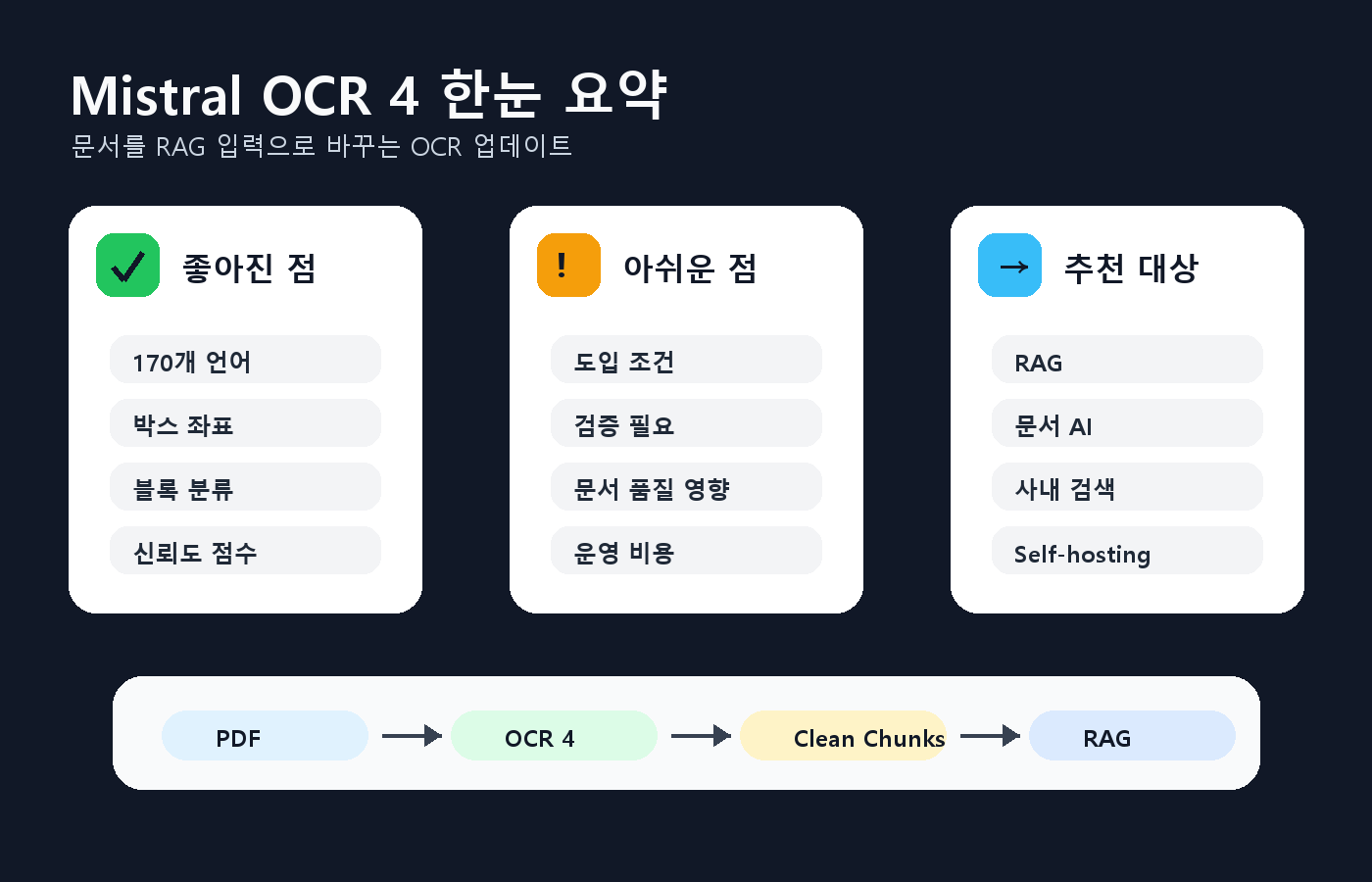
좋은 점
- 170개 언어 지원으로 다국어 문서 처리 폭이 넓다.
- 바운딩 박스, 블록 분류, 신뢰도 점수가 RAG와 검수 UI에 바로 도움이 된다.
- 단일 컨테이너 self-hosting을 내세워 민감한 기업 문서 처리 시 선택지가 늘어난다.
아쉬운 점
- 한국어 실문서, 복잡한 표, 흐린 스캔에서의 체감 품질은 아직 확인 필요다.
- self-hosting은 인프라와 라이선스 조건까지 봐야 하므로 바로 가볍게 도입할 수 있는 기능은 아니다.
- OCR 결과가 구조화된다고 해서 문서 이해나 답변 품질이 자동으로 완성되는 것은 아니다.
내 생각
이번 발표는 화려한 챗봇 기능은 아니지만, 문서 AI를 실제 업무에 넣을 때 꽤 중요한 방향이다. 많은 RAG 프로젝트가 모델 성능보다 입력 문서 품질에서 막힌다. PDF를 텍스트로만 뽑아 넣으면 표, 제목, 캡션, 원문 위치가 흐려지고, 답변이 맞아도 근거를 확인하기 어렵다.
OCR 4가 말하는 바운딩 박스와 신뢰도 점수는 이 문제를 줄이는 쪽에 있다. 특히 사내 검색, 계약서 검토, 기술 문서 QA처럼 "답이 어디서 나왔는지"를 물어보는 업무에서는 단순 추출률보다 근거 추적이 더 중요해진다.
경쟁 모델과 비교했을 때도 포인트는 명확하다. Mistral OCR 4는 범용 대화 모델의 부가 기능이라기보다, 문서 처리 파이프라인에 꽂아 쓰는 전용 부품에 가깝다. 그래서 소비자용 AI 뉴스보다는 기업 문서 자동화 쪽에서 더 의미가 커 보인다.
결론
Mistral OCR 4의 핵심은 OCR을 "글자 추출"에서 "구조화된 문서 입력"으로 끌어올린 데 있다. 170개 언어, 바운딩 박스, 블록 분류, 신뢰도 점수, self-hosting 옵션은 문서 AI와 RAG를 만드는 팀에게 꽤 실용적인 재료다.
한 줄 평: "문서를 읽는 AI보다, 문서를 AI가 읽기 좋게 만드는 기술이 먼저 좋아지고 있다."
여러분이 쓰는 문서 AI에서 제일 자주 막히는 부분은 OCR 품질인지, 검색 정확도인지, 아니면 출처 확인인지 댓글로 남겨줘도 좋겠다.