Hugging Face Jobs와 vLLM: 실험용 LLM 서버가 쉬워졌다
Hugging Face Jobs 공식 가이드 공개, 핵심은 vLLM 기반 OpenAI 호환 엔드포인트를 한 명령으로 띄우는 흐름이었다
한눈에 보기
- 발표 내용: Hugging Face가 HF Jobs 위에서 vLLM 서버를 실행하고 외부에서 OpenAI 호환 API처럼 호출하는 공식 가이드를 공개했다.
- 핵심 변화:
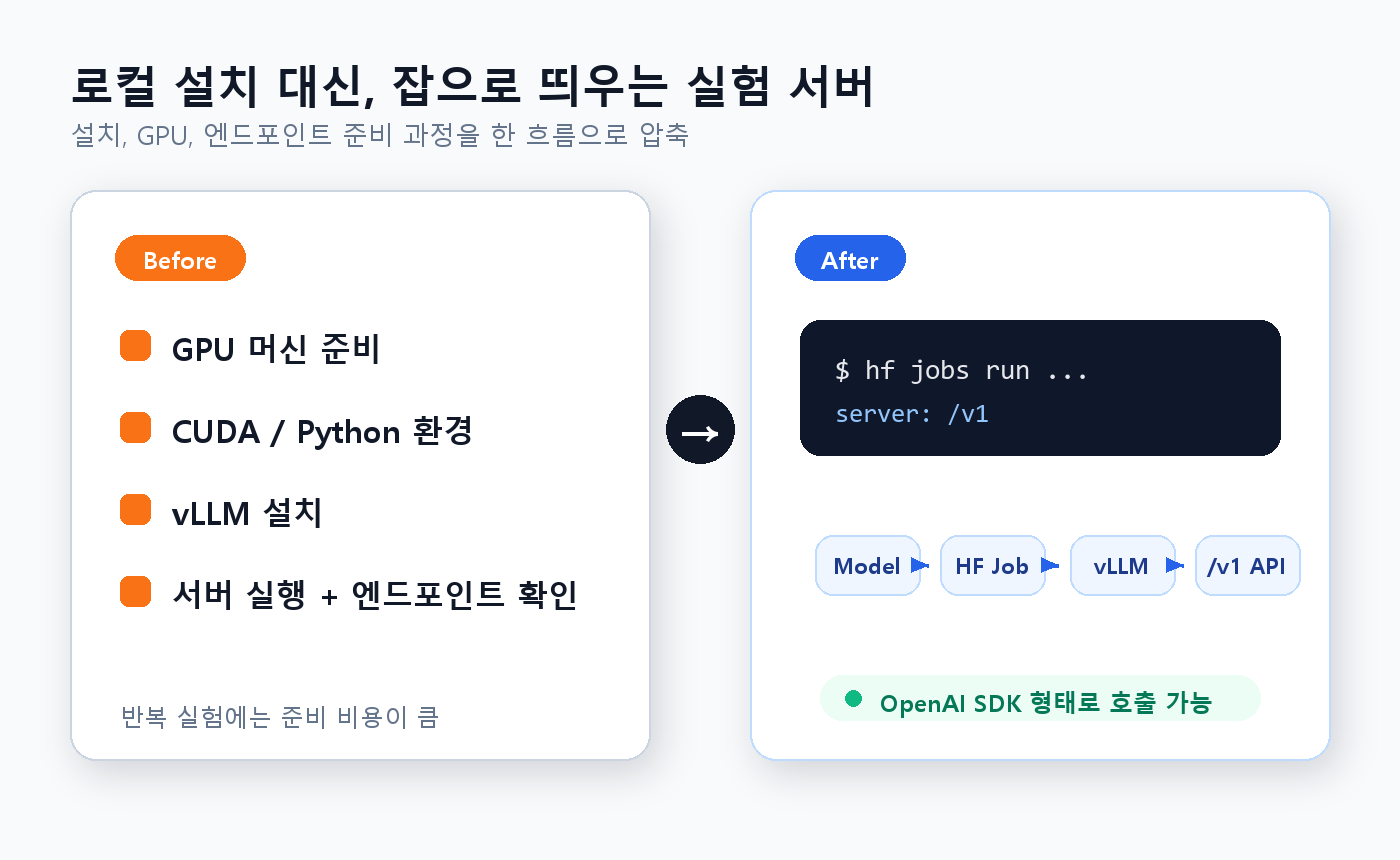
hf jobs run명령으로 GPU, Docker 이미지, vLLM 서버, 노출 포트를 한 번에 묶어 임시 LLM 서버를 띄울 수 있다. - 한 줄 결론: 운영형 제품보다는 테스트, 평가, 배치 생성, 데모용 LLM 서버를 빠르게 세우는 데 잘 맞는 방식이다.

이번 발표, 뭐가 나왔나
Hugging Face 공식 블로그의 주제는 간단하다. HF Jobs에서 vllm/vllm-openai 이미지를 실행하고, --expose 8000으로 vLLM 포트를 외부에 노출한 뒤, OpenAI 호환 클라이언트나 curl로 호출하는 흐름이다.
예시에서는 Qwen 모델을 vLLM으로 서빙하고, 생성된 https://<job_id>--8000.hf.jobs 형태의 URL을 /v1 베이스 URL로 사용한다. 요청에는 Hugging Face 토큰이 필요하며, 일반 브라우저에서 공개 페이지처럼 여는 방식은 아니다.
즉 이번 발표의 포인트는 “새로운 모델 출시”라기보다, Hugging Face 인프라에서 짧게 쓰는 LLM API 서버를 더 가볍게 띄우는 공식 레시피가 나왔다는 쪽에 가깝다.
핵심 변화 3가지
1. vLLM 서버 실행이 한 명령 흐름으로 정리됐다
기존에는 GPU 서버를 잡고, Docker 환경을 맞추고, 포트와 인증을 따로 고민하는 일이 필요했다. 이번 가이드는 hf jobs run, GPU flavor, vLLM 이미지, vllm serve, 포트 노출을 한 줄 흐름으로 묶어 보여준다.
이전과 비교하면 실험 초반의 준비 시간이 줄어든다. 모델 성능을 보기도 전에 서버 구성에서 지치는 일이 줄어드는 셈이다.
2. OpenAI 호환 API로 바로 붙일 수 있다
vLLM은 OpenAI 호환 HTTP API를 지원한다. Hugging Face 예시도 OpenAI Python 클라이언트의 base_url을 HF Jobs의 노출 URL로 바꾸고, HF 토큰을 API 키처럼 넣는 방식이다.
개발자 입장에서는 기존 OpenAI 클라이언트 기반 코드 일부를 바꿔 실험해볼 여지가 생긴다. 완전히 새 SDK를 익히는 일이 아니라, 이미 쓰던 호출 방식을 다른 서버에 붙여보는 느낌에 가깝다.
3. “임시 서버”라는 성격이 분명하다
HF Jobs 문서에서는 Jobs가 평가 실행, 데이터 라벨링 세션, 프롬프트 반복 실험, 짧은 데모처럼 endpoint 자체가 제품이 아닌 상황에 적합하다고 설명한다. 반대로 안정적인 장기 운영, 오토스케일링, 모니터링, 고정 URL이 필요하면 Inference Endpoints가 더 맞는 선택지로 소개된다.
이 구분이 꽤 중요하다. 빠르게 띄워서 실험하는 도구와, 고객 트래픽을 계속 받는 운영 도구는 요구사항이 다르기 때문이다.
그래서 실제로 뭐가 달라지나
일반 사용자 기준
일반 사용자가 바로 체감할 서비스형 기능은 아니다. URL도 공개 웹페이지처럼 열 수 없고, HF 토큰이 필요하다. 다만 개발자들이 모델 테스트와 데모를 더 빨리 만들 수 있으면, 결과적으로 실험적인 AI 기능을 더 빠르게 접할 가능성은 있다.
개발자 기준
가장 직접적인 변화가 있다. vLLM 서버를 빠르게 띄우고, OpenAI 호환 API로 붙이고, 필요가 끝나면 hf jobs cancel <job_id>로 종료하는 흐름이 명확해졌다. 큰 모델을 쓸 때는 더 강한 GPU flavor와 --tensor-parallel-size 같은 vLLM 옵션을 조합할 수 있다.
핵심은 “서버를 만들었다”가 아니라 “실험을 시작할 수 있는 상태까지 가는 길이 짧아졌다”는 점이다.
창업자/업무 활용 기준
프로덕션 서비스를 바로 대체하기보다는, 모델 후보 비교, 내부 데모, 일회성 배치 생성, 평가 파이프라인에 적합하다. “이 모델로 우리 업무가 돌아갈까?”를 확인하는 초기 실험 비용과 시간을 줄이는 쪽에 의미가 있다.
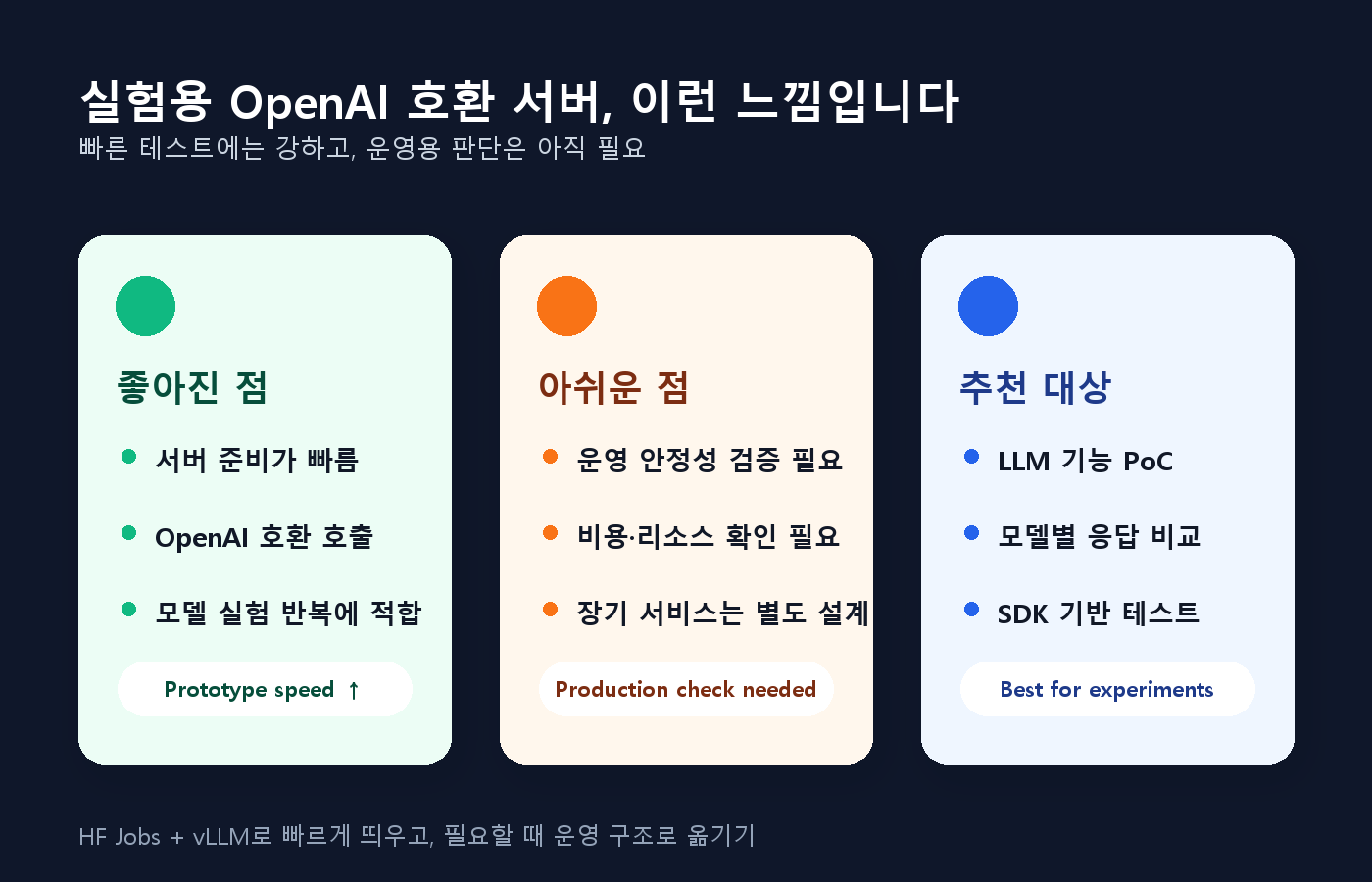
좋은 점
- 시작 장벽이 낮다. 서버 프로비저닝이나 Kubernetes 없이 HF Jobs 명령으로 GPU 기반 vLLM 서버를 띄우는 흐름을 제시한다.
- 기존 클라이언트와 연결하기 쉽다. OpenAI 호환 API 형태라 Python OpenAI 클라이언트,
curl, 노트북, 에이전트 도구와 연결하는 그림이 자연스럽다. - 짧게 쓰고 끄는 구조가 명확하다. timeout을 걸 수 있고, 작업이 끝나면 job을 취소하는 방식이다.
- 운영 목적 구분도 비교적 솔직하다. HF Jobs는 실험과 임시 서버에, Inference Endpoints는 더 관리형이고 장기적인 엔드포인트에 맞다고 선을 긋는다.
아쉬운 점
- 토큰과 CLI 사용이 전제라서 비개발자용 기능은 아니다. 공개 챗봇 링크처럼 공유하는 방식도 아니다.
- 서버 준비 시간이 있다. 이미지 pull, 모델 다운로드, 모델 로딩을 거쳐야 하며, 로그에서 준비 완료 상태를 확인해야 한다.
- 큰 모델은 여전히 튜닝이 필요하다. 예시에서도 GPU 수에 맞춘 tensor parallel 설정, context 길이와 동시 sequence 수 조정 같은 옵션이 등장한다.
- 과금 단위와 실제 비용은 아직 확인 필요다. 공식 블로그와 문서의 표현이 다르게 보일 수 있어, 실제 사용 전에는 현재 가격 페이지와 CLI 출력 기준으로 다시 봐야 한다.
내 생각
이번 발표는 “LLM 서빙이 완전히 쉬워졌다”보다는 “실험용 LLM 서버를 만드는 첫 단계가 확 줄었다”에 가깝다. 특히 vLLM을 이미 쓰고 있거나, OpenAI 호환 API 형태로 내부 도구를 붙이는 팀이라면 꽤 실용적인 업데이트다.
반대로 이걸 바로 고객용 서비스의 백엔드로 쓰는 건 조심해야 한다. HF Jobs는 사라지는 임시 endpoint라는 성격이 강하고, 접근 제어와 운영 편의성도 Inference Endpoints와 역할이 다르다.
그래서 개인적으로는 평가, 배치 생성, 모델 후보 테스트, 에이전트 백엔드 실험 같은 곳에 먼저 떠올릴 만한 선택지라고 본다.
결론
Hugging Face Jobs와 vLLM 조합은 프로덕션 대체재라기보다, LLM 서버 실험의 준비 시간을 줄이는 실용적인 지름길에 가깝다. 서버를 오래 운영해야 한다면 다른 선택지를 봐야 하지만, 빠르게 모델을 띄우고 API로 때려보는 목적이라면 꽤 매력적인 흐름이다.
한 줄 평: “HF Jobs의 vLLM 원커맨드는 운영용 고속도로가 아니라, 실험실 문을 빨리 여는 열쇠에 가깝다.”
여러분이라면 이걸 모델 평가용으로 먼저 써볼까요, 아니면 내부 데모 서버용으로 먼저 써볼까요?