Gemini Nano MTP: Pixel 온디바이스 AI가 빨라진 이유
Google Gemini Nano MTP 공개, 핵심은 폰 안에서 AI 답변을 더 빨리 만드는 구조였다
한눈에 보기
- 발표 내용: Google Research가 Pixel의 Gemini Nano v3에 frozen Multi-Token Prediction을 적용한 기술 글을 공개했다.
- 핵심 변화: 한 번에 한 토큰씩 생성하는 병목을 줄이고, 후보 토큰을 먼저 예측한 뒤 본 모델이 검증하는 방식으로 온디바이스 생성 속도를 높였다.
- 한 줄 결론: 새 챗봇 기능 발표라기보다, Pixel 안에서 AI 답변을 덜 기다리게 만드는 엔진 튜닝에 가깝다.
이번 발표, 뭐가 나왔나
Google Research가 2026년 6월 26일 Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction이라는 공식 기술 글을 공개했다. 주제는 Pixel 안에서 돌아가는 Gemini Nano v3의 생성 속도를 어떻게 끌어올렸는지다.
핵심은 frozen MTP, 즉 frozen Multi-Token Prediction이다. 기존 autoregressive decoding은 답변을 만들 때 다음 토큰을 하나 예측하고, 그다음 토큰을 또 예측하는 식으로 진행된다. 이 방식은 구조가 단순하지만 스마트폰처럼 전력과 메모리 제약이 큰 환경에서는 지연으로 이어질 수 있다.
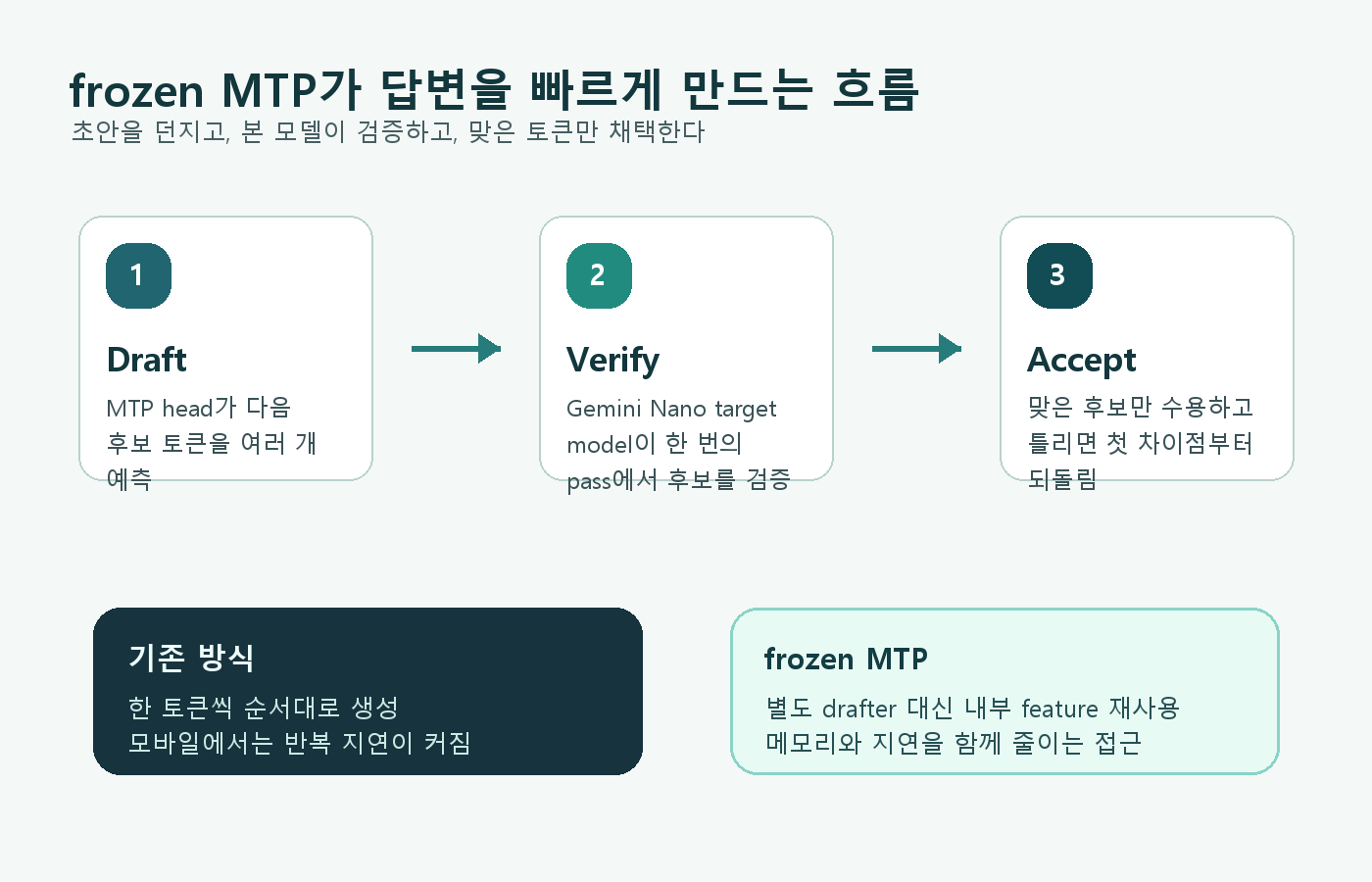
Google은 draft tokens를 먼저 예측하고, Gemini Nano target model이 한 번의 pass에서 그 후보를 검증하는 방식을 설명했다. 맞은 후보 토큰만 받아들이고, 틀리면 첫 차이점부터 되돌리는 구조다.
핵심 변화 3가지
1. Gemini Nano가 한 토큰씩만 기다리는 병목을 줄였다
기존 방식에서는 AI 답변이 한 토큰씩 순서대로 만들어진다. 서버에서는 이 지연이 상대적으로 덜 보일 수 있지만, 스마트폰 안에서 바로 답변해야 하는 기능에서는 체감 속도와 배터리에 영향을 준다.
frozen MTP는 다음에 나올 후보 토큰을 미리 던지고, 본 모델이 그 후보를 확인하는 방식이다. 사용자는 기술 이름을 몰라도 된다. 알림 요약이나 문장 교정 같은 기능에서 답변 생성 시간이 줄어드는 쪽이 사용자 입장에서는 먼저 보인다.
2. 별도 drafter model 대신 내부 feature를 활용했다
일반적인 speculative decoding에서는 작은 drafter model이 후보 토큰을 만들고, 큰 verifier model이 검증한다. 문제는 스마트폰에서는 이 작은 모델도 메모리와 연산 비용을 먹는다는 점이다.
Google이 설명한 frozen MTP는 별도 drafter model을 붙이는 대신 target model 내부 feature와 기존 cache를 활용한다. 공식 글에서는 standalone drafter와 비교해 instance당 약 130MB의 메모리 절감을 관찰했다고 설명한다.
3. Pixel 9/10의 실제 온디바이스 기능과 연결된다
Google은 이 접근이 Pixel 9 및 Pixel 10 시리즈에 적용됐고, AI Notification Summaries와 Proofread 같은 기능의 텍스트 생성이 더 빨라지고 에너지 사용도 줄어든다고 설명한다.
또 Pixel 9 기기에서 일부 작업은 standalone drafter와 비교해 50% 이상의 speedup을 보였다고 밝혔다. 다만 이 수치는 Google 공식 글의 실험 맥락에 있는 숫자다. 모든 앱, 모든 문장, 모든 사용자 환경에서 같은 체감 개선이 나온다고 단정하면 안 된다.
그래서 실제로 뭐가 달라지나
일반 사용자 기준
가장 직접적인 변화는 폰 안에서 AI가 답변을 만드는 시간이 줄어들 수 있다는 점이다. 알림 요약, 문장 교정, 짧은 답변 생성처럼 몇 초만 느려도 답답한 기능에서 이런 최적화가 의미를 가진다.
온디바이스 AI는 데이터를 매번 클라우드로 보내지 않고 기기 안에서 처리한다는 장점이 있다. 대신 기기 성능, 메모리, 배터리라는 현실적인 제약을 정면으로 맞는다. frozen MTP는 이 제약 안에서 속도를 끌어올리려는 접근이다.
개발자 기준
개발자 입장에서는 온디바이스 AI 경쟁의 기준이 단순히 모델 크기나 지능만은 아니라는 점이 보인다. 같은 모델이라도 decoding 구조, cache 활용, 메모리 footprint가 사용자 경험을 크게 바꿀 수 있다.
Google의 Android Developers 문서는 Gemini Nano가 Android 기기에서 온디바이스 생성형 AI 기능을 제공하는 모델이라고 설명한다. 이런 흐름에서는 모델을 어떻게 배포하고, 어떻게 빠르게 실행하느냐가 앱 경험의 일부가 된다.
창업자/업무 활용 기준
AI 기능을 제품에 붙이는 팀이라면 “클라우드 AI냐, 온디바이스 AI냐”를 단순 성능 비교로만 보면 부족하다. 사용자가 기다리는 시간, 네트워크 의존도, 비용, 기기 내 처리의 장점까지 같이 봐야 한다.
특히 모바일 앱에서 짧은 텍스트 보조 기능을 만들고 있다면 이런 최적화 흐름은 체크할 만하다. 대형 모델을 더 크게 만드는 것보다, 작은 모델을 더 빠르고 안정적으로 돌리는 쪽이 실제 제품에서는 더 먼저 체감될 수 있다.
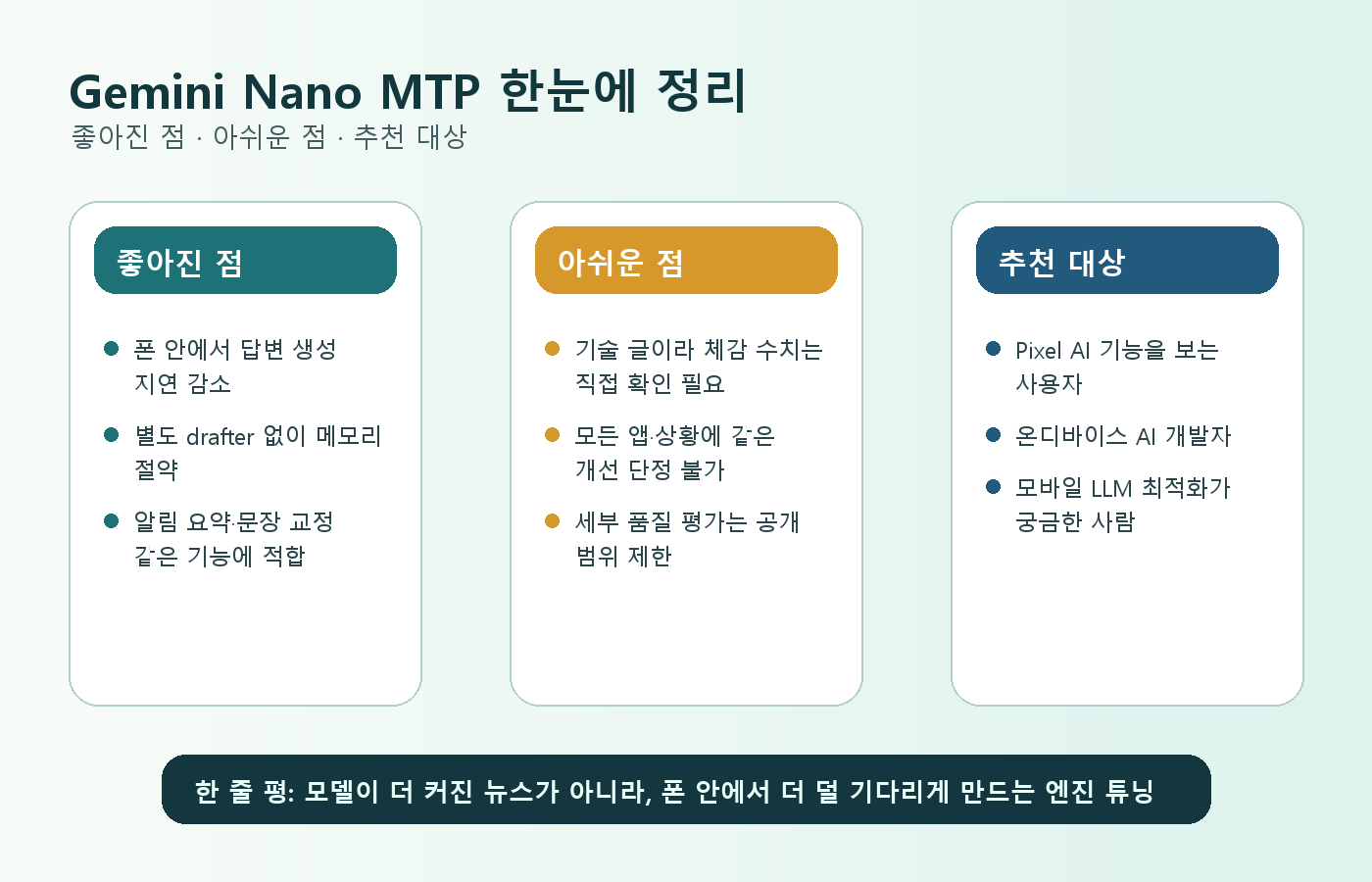
좋은 점
- Pixel 온디바이스 AI의 병목을 줄이는 기술적 방향이 공식 글로 정리됐다.
- 별도 drafter model 없이 내부 feature를 활용해 모바일 메모리 부담을 줄이는 접근이다.
- 일부 Pixel 9 작업에서 50% 이상 speedup, instance당 약 130MB 절감이라는 구체적인 근거가 제시됐다.
아쉬운 점
- 일반 사용자가 설정 화면에서 바로 확인하는 기능 발표라기보다는 내부 추론 최적화에 가깝다.
- 50% 이상 speedup은 공식 글의 비교 맥락에 있는 수치라 모든 환경에 그대로 적용된다고 볼 수는 없다.
- draft token acceptance와 품질 평가의 세부 조건은 공개 글 범위 안에서만 확인 가능하다.
내 생각
이번 발표에서 핵심은 “모바일 AI는 결국 속도 싸움”이라는 점이다. AI 기능이 아무리 좋아도 폰 안에서 답이 늦게 나오면 사용자는 바로 답답함을 느낀다. 특히 알림 요약이나 문장 교정처럼 짧고 자주 쓰는 기능은 더 그렇다.
frozen MTP는 이 문제를 꽤 실용적으로 건드린다. 별도 작은 모델을 하나 더 붙이는 대신, 이미 target model이 계산한 내부 정보를 활용한다. 쉽게 말하면 AI가 답을 쓰기 전에 몇 단어를 미리 적어보고, 본 모델이 맞는지만 확인하는 구조다.
개인적으로는 이걸 새 기능 발표보다 엔진 튜닝에 가깝게 본다. 사용자는 frozen MTP라는 이름을 몰라도 된다. 다만 Pixel에서 알림 요약이나 문장 교정이 더 자연스럽고 빠르게 느껴진다면, 이런 최적화가 뒤에서 일하고 있을 가능성이 있다.
결론
Google Research의 frozen MTP 글은 Gemini Nano v3가 Pixel 안에서 더 빠르게 답변을 만들도록 하는 기술적 접근을 설명한다. 한 토큰씩 생성하는 병목을 줄이고, 후보 토큰을 먼저 예측한 뒤 target model이 검증하는 방식이다.
특히 별도 drafter model 없이 target model 내부 feature를 활용한다는 점이 모바일 환경과 잘 맞는다. 모델이 더 커졌다는 뉴스가 아니라, 같은 기기 안에서 더 빠르고 가볍게 움직이도록 만든 변화로 보는 게 정확하다.
한 줄 평: “폰 안에서 AI 답변을 더 빠르게 만들기 위해, Google이 모델의 초안 작성 방식을 손본 업데이트.”
온디바이스 AI에서 더 중요하다고 보는 쪽은 속도인가요, 아니면 클라우드급 품질인가요? 댓글로 의견을 남겨주세요.