OpenAI Jalapeno AI 칩 발표, 핵심은 ChatGPT 추론 비용을 줄이는 전략이었다
OpenAI Jalapeno 공개, 핵심은 LLM 추론에 맞춘 자체 Intelligence Processor였다
한눈에 보기
- 발표 내용: OpenAI와 Broadcom이 LLM 추론에 최적화한 OpenAI의 첫 Intelligence Processor
Jalapeno를 공개했다. - 핵심 변화: 모델만 만드는 단계를 넘어, ChatGPT와 Codex를 돌리는 하드웨어 계층까지 OpenAI가 직접 설계하기 시작했다.
- 한 줄 결론: 성능표는 아직 기다려야 하지만, AI 경쟁의 병목이 모델에서 추론 인프라로 내려왔다는 신호다.
이번 발표, 뭐가 나왔나
OpenAI와 Broadcom은 2026년 6월 24일 LLM 추론용 칩 Jalapeno를 발표했다. OpenAI는 이 칩을 자사의 첫 Intelligence Processor라고 부르며, ChatGPT, Codex, API, 향후 에이전트형 제품에서 실제로 발생하는 추론 패턴을 반영했다고 설명했다.
핵심은 범용 AI 가속기를 살짝 고쳐 쓰는 방식이 아니라는 점이다. OpenAI는 커널, 메모리 이동, 네트워킹, 서빙 패턴을 기준으로 처음부터 LLM inference에 맞춘 설계라고 밝혔다. Broadcom은 실리콘 구현과 네트워킹을, Celestica는 보드와 랙 시스템 쪽을 맡는 구조다.
핵심 변화 3가지
1. OpenAI가 모델 아래의 칩까지 직접 설계한다
Jalapeno는 OpenAI가 제품, 모델, API를 넘어 인프라 하단까지 직접 맞추려는 full-stack 전략의 결과물이다. OpenAI는 이 칩이 현재와 미래 LLM의 추론 요구를 기준으로 설계됐고, ChatGPT와 Codex 같은 실제 서비스 운영 경험이 반영됐다고 설명했다.
이전과 비교했을 때 중요한 점은 병목의 위치다. 모델이 아무리 좋아져도 사용자가 체감하는 속도, 가격, 안정성은 추론 인프라가 받쳐줘야 나온다. OpenAI가 자체 칩을 공개한 이유도 결국 더 많은 AI 요청을 더 싸고 안정적으로 처리하기 위한 쪽에 가깝다.
2. 9개월 tape-out, AI가 AI 칩 설계에도 들어갔다
OpenAI와 Broadcom은 Jalapeno가 초기 설계부터 manufacturing tape-out까지 9개월 만에 진행됐다고 밝혔다. 그리고 이 과정에서 OpenAI 모델이 설계와 최적화 일부를 가속하는 데 쓰였다고 설명했다.
사용자 입장에서는 당장 버튼 하나가 생기는 변화는 아니다. 다만 AI가 소프트웨어 코딩을 돕는 수준을 넘어, 다음 세대 AI 인프라 설계 속도에도 영향을 주기 시작했다는 점은 꽤 상징적이다.
3. 성능/W 개선을 말했지만, 세부 벤치마크는 아직 공개 전이다
OpenAI는 초기 테스트 기준으로 Jalapeno의 performance per watt가 현재 state-of-the-art보다 높을 것이라고 밝혔다. 칩은 생산 목표 주파수와 전력에서 ML workloads를 실행 중이고, GPT-5.3-Codex-Spark도 랩에서 돌고 있다고 공개했다.
다만 여기서 흥분은 조금 아껴야 한다. 구체적인 성능 수치, 비교 대상, 전력 조건, 실제 대규모 배포 결과는 아직 나오지 않았다. OpenAI는 자세한 기술 보고서를 향후 공개하겠다고 했다.
그래서 실제로 뭐가 달라지나
일반 사용자 기준
일반 사용자가 바로 "Jalapeno 모드"를 켜는 변화는 아니다. 하지만 장기적으로는 ChatGPT 응답 속도, 혼잡 시간 안정성, 더 긴 에이전트 작업의 대기 시간 같은 부분에 영향을 줄 수 있다.
핵심은 이거다. 추론 칩이 좋아지면 같은 전력과 비용으로 더 많은 답변을 만들 수 있다. 그 결과가 실제 제품 가격이나 사용 한도에 어떻게 반영될지는 아직 확인 필요지만, 방향은 분명하다.
개발자 기준
개발자에게는 API 비용 구조와 latency가 가장 먼저 보일 가능성이 있다. OpenAI는 Jalapeno가 ChatGPT, Codex, API, agentic products의 서빙 패턴을 반영했다고 밝혔다. 즉 개발자 도구와 API도 이 인프라 전략의 수혜 대상에 들어간다.
다만 API 가격 인하, 특정 모델의 latency 개선, 외부 고객이 Jalapeno 기반 용량을 직접 선택할 수 있는지 같은 세부 사항은 아직 공개되지 않았다. 지금 단계에서는 "인프라 방향성"으로 보는 게 맞다.
창업자/업무 활용 기준
AI 제품을 만드는 팀이라면 이번 발표를 모델 성능 뉴스로만 보면 아쉽다. 실제 비용은 추론에서 계속 쌓인다. 사용자 수가 늘고, 에이전트가 더 오래 작업하고, API 호출이 많아질수록 칩과 데이터센터 효율이 곧 사업 모델이 된다.
그래서 Jalapeno는 OpenAI 한 회사의 칩 뉴스이면서, 동시에 AI 서비스의 원가 경쟁이 어디에서 벌어지는지 보여주는 사례다. 모델 선택만큼이나 인프라, 지연시간, 사용량 제한, 안정성도 같이 봐야 한다.
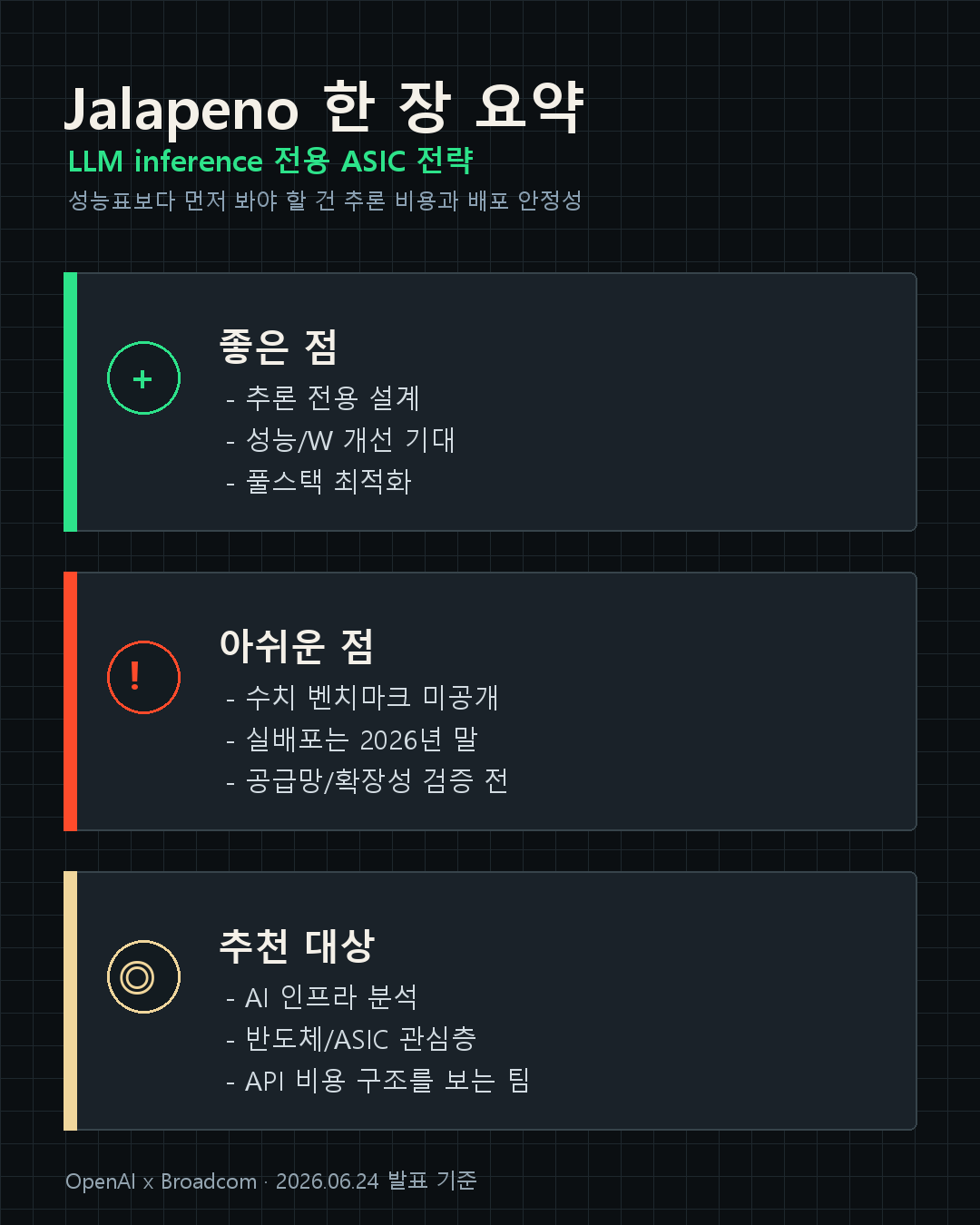
좋은 점
- LLM 추론에 맞춘 전용 설계라 ChatGPT, Codex, API 운영 맥락과 잘 맞는다.
- Broadcom, Celestica와 함께 칩부터 랙 시스템까지 이어지는 플랫폼 전략을 잡았다.
- 9개월 tape-out 사례는 AI가 하드웨어 개발 주기에도 들어가고 있음을 보여준다.
아쉬운 점
- 구체적인 성능 벤치마크와 비교 조건은 아직 공개되지 않았다.
- 초기 배포 목표가 2026년 말이라 실제 체감 변화까지는 시간이 필요하다.
- 공급망, 대규모 배포 안정성, API 가격 반영 여부는 아직 확인 필요다.
내 생각
이번 발표는 "OpenAI가 Nvidia를 대체한다"처럼 단순하게 볼 뉴스는 아니다. OpenAI는 앞으로도 여러 종류의 가속기를 쓸 가능성이 크고, Jalapeno도 그중 하나의 축으로 보는 편이 더 현실적이다.
그래도 방향은 꽤 선명하다. AI 경쟁은 이제 모델 이름과 벤치마크만으로 설명하기 어렵다. 누가 더 싸게, 더 빠르게, 더 안정적으로 추론을 돌릴 수 있느냐가 제품 경쟁력으로 이어진다.
경쟁 구도로 보면 Google TPU, AWS Trainium/Inferentia, Meta MTIA처럼 큰 플레이어들이 각자 자기 워크로드에 맞춘 칩을 갖는 흐름과 닿아 있다. OpenAI도 결국 같은 길로 들어섰다. 차이는 OpenAI가 ChatGPT와 Codex라는 대규모 실제 제품 사용량을 바탕으로 칩 설계를 설명하고 있다는 점이다.
결론
OpenAI Jalapeno는 아직 성능표가 완성된 제품 발표라기보다, OpenAI의 인프라 전략을 드러낸 발표에 가깝다. 모델을 잘 만드는 회사가 이제 그 모델을 돌리는 칩, 메모리, 네트워크, 랙 시스템까지 맞추려 한다.
당장 사용자가 느낄 변화는 제한적일 수 있다. 하지만 ChatGPT, Codex, API 사용량이 계속 늘어난다면, 이런 추론 전용 칩은 가격과 속도, 안정성을 좌우하는 핵심 부품이 될 가능성이 크다.
한 줄 평: "AI 모델 경쟁의 다음 장은 답변을 얼마나 싸고 빠르게 만들 수 있느냐로 내려가고 있다."
AI 칩 경쟁을 볼 때 성능 벤치마크와 실제 서비스 가격 중 어느 쪽을 더 먼저 봐야 한다고 생각하는지 댓글로 남겨줘도 좋겠다.