Anthropic Alibaba Claude 논란, 핵심은 2,880만 번의 distillation 의혹이었다
Anthropic/Claude 보도, 핵심은 모델 출력으로 경쟁 AI를 학습시키는 distillation 리스크였다
한눈에 보기
- 발표 내용: Reuters와 주요 매체가 Anthropic의 서한을 근거로 Alibaba 측의 Claude 능력 추출 의혹을 보도했다.
- 핵심 변화: Anthropic은 4월 22일부터 6월 5일까지 약 2,880만 건의 Claude 교환과 약 2만5,000개 부정 계정이 동원됐다고 주장했다.
- 한 줄 결론: 이번 이슈는 AI 모델 경쟁이 성능 싸움에서 접근 통제와 출력 데이터 보안 싸움으로 넘어가고 있다는 신호다.
이번 발표, 뭐가 나왔나
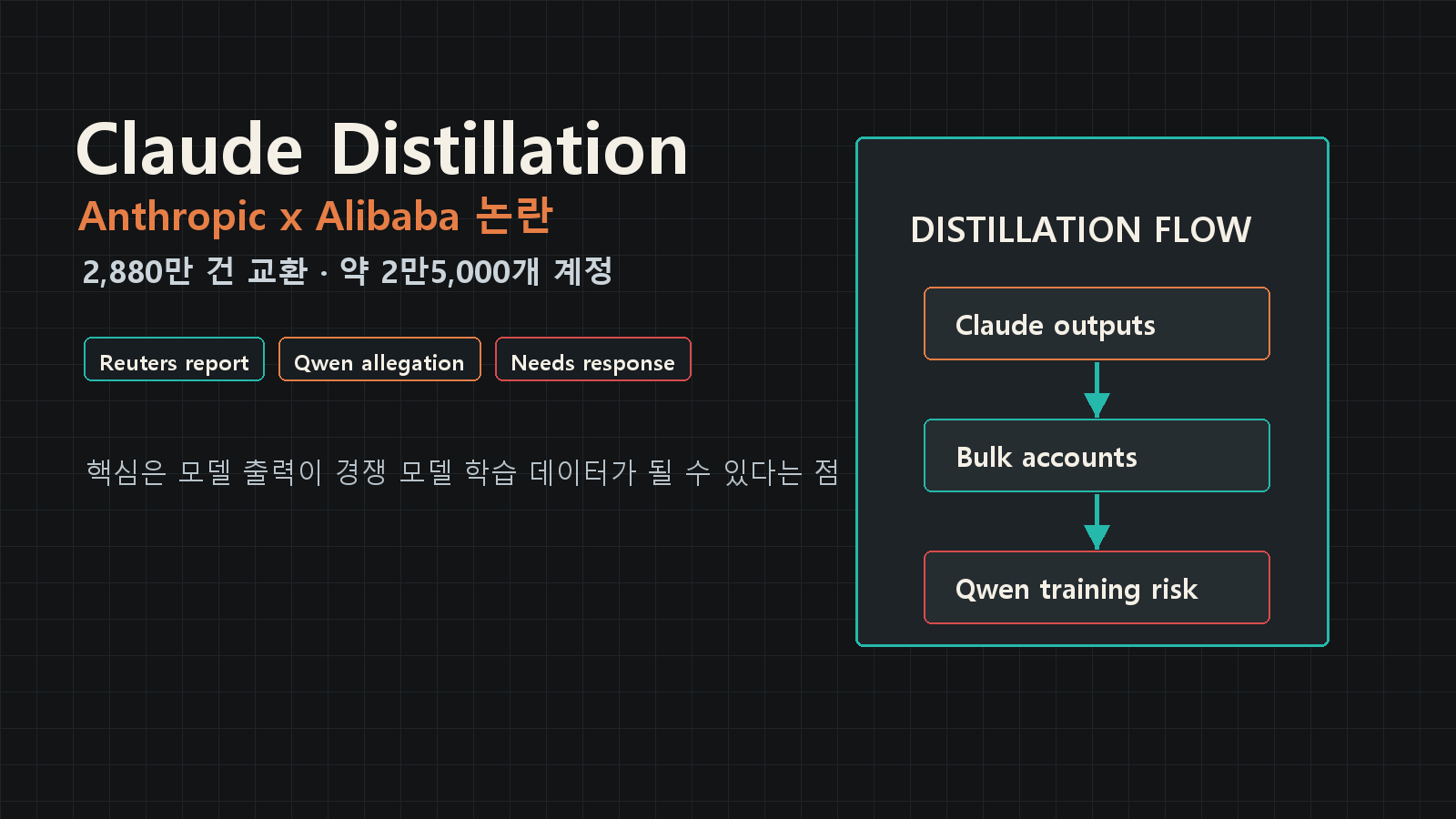
Reuters가 확인한 Anthropic의 서한에 따르면, Anthropic은 Alibaba와 Alibaba AI Lab Qwen에 연계된 운영자들이 Claude의 능력을 대규모로 추출했다고 주장했다. 방식은 distillation으로 설명됐다. 쉽게 말해 더 강한 모델의 출력값을 반복적으로 받아, 다른 모델을 훈련시키는 데 쓰는 방식이다.
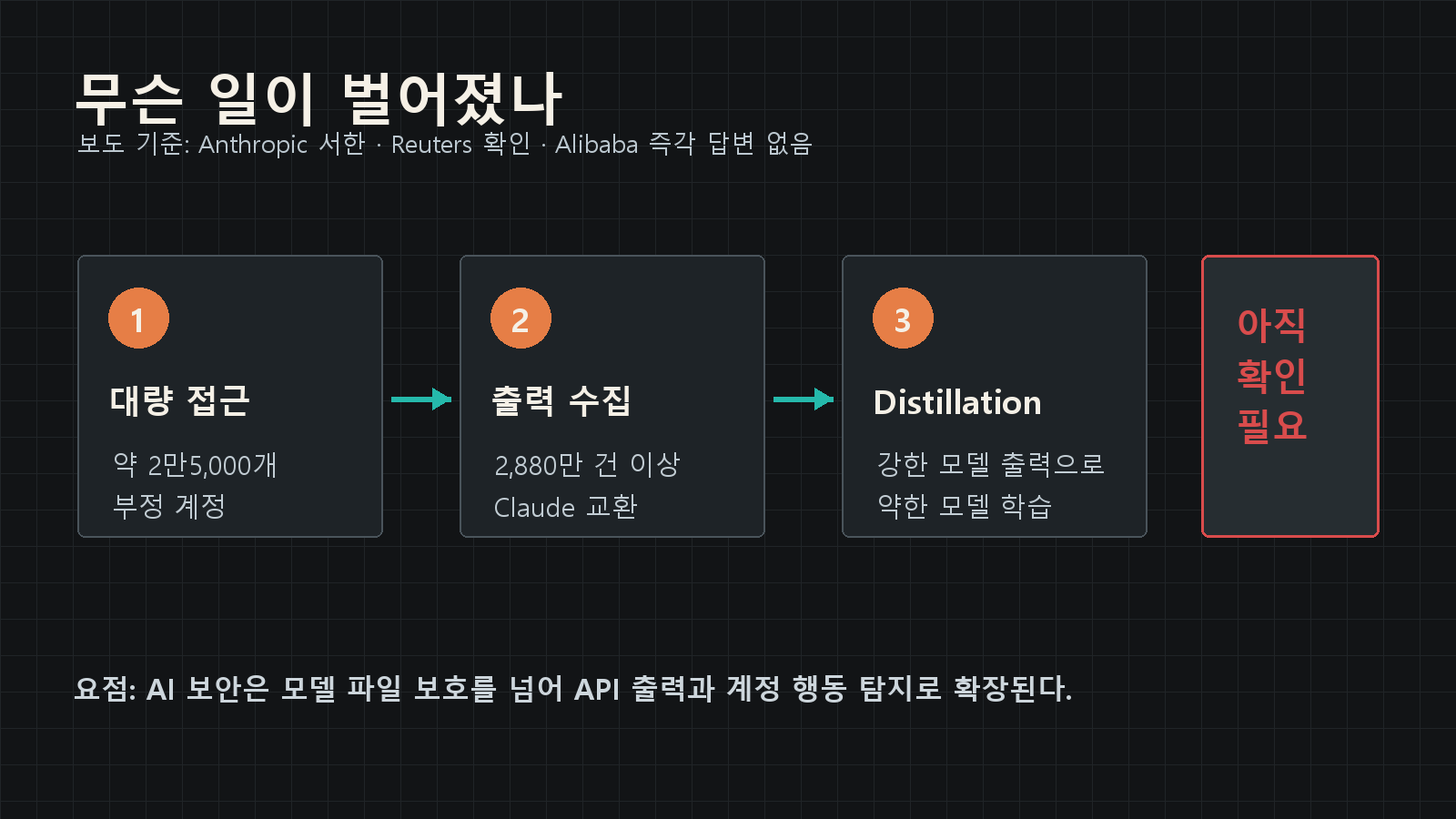
보도에 따르면 이 캠페인은 2026년 4월 22일부터 6월 5일까지 이어졌고, 거의 2만5,000개 부정 계정을 통해 2,880만 건 이상의 Claude 교환을 만들었다. Alibaba 측은 Reuters의 논평 요청에 즉각 응답하지 않은 것으로 보도됐다. 이 부분은 아직 확인 필요다.
핵심 변화 3가지
1. Anthropic은 이번 일을 '가장 큰 distillation 공격'으로 봤다
Anthropic은 서한에서 이번 캠페인을 자사 기준 최대 규모의 distillation 공격으로 설명했다. 단순한 무단 사용이 아니라, Claude의 소프트웨어 엔지니어링과 추론 능력을 대량 출력으로 뽑아내려 한 시도라는 게 핵심 주장이다.
이게 사실이라면 AI 회사 입장에서는 API 남용 차단, 계정 검증, 출력 패턴 탐지 같은 운영 보안이 모델 성능만큼 중요해진다.
2. 숫자가 크다: 2,880만 교환과 약 2만5,000개 계정
보도에서 가장 눈에 띄는 건 규모다. Anthropic은 2026년 4월 22일부터 6월 5일까지 약 2,880만 건 이상의 Claude 교환이 발생했고, 거의 2만5,000개 부정 계정이 쓰였다고 주장했다.
일반 사용자가 몇 번 써보는 수준이 아니다. 모델 출력 데이터를 체계적으로 모으는 작업이었다는 의심이 나오는 이유다.
3. AI 경쟁의 쟁점이 '모델을 누가 더 잘 만드나'에서 '누가 접근을 통제하나'로 넓어졌다
이 이슈는 단순히 Anthropic과 Alibaba 사이의 분쟁으로만 볼 일이 아니다. 강한 모델의 출력값이 다른 모델 학습에 쓰일 수 있다면, AI 기업은 모델 자체뿐 아니라 사용량 패턴, 계정 생성, API 접근, 국가별 규제까지 함께 관리해야 한다.
특히 Anthropic이 올해 초부터 distillation 공격과 지역별 접근 제한을 반복해서 강조해 온 흐름과도 맞물려 있다. AI 모델이 점점 안보와 산업정책의 영역으로 들어가고 있다는 뜻이다.
그래서 실제로 뭐가 달라지나
일반 사용자 기준
일반 사용자 입장에서는 당장 Claude 사용법이 바뀌는 뉴스는 아니다. 다만 앞으로 강력한 AI 모델은 로그인, 사용량 제한, 이상 사용 탐지, 지역별 접근 제한이 더 빡빡해질 가능성이 있다.
개발자 기준
API를 쓰는 개발자에게는 계정 신뢰도와 사용 패턴 관리가 더 중요해질 수 있다. 짧은 시간에 대량 호출을 만들거나 출력 데이터를 조직적으로 수집하는 패턴은 더 강하게 막힐 가능성이 크다.
창업자/업무 활용 기준
AI 제품을 만드는 팀이라면 단순히 모델을 붙이는 것에서 끝나지 않는다. 고객 인증, 호출량 제한, 로그 분석, 데이터 사용 약관, 악용 탐지까지 설계해야 한다. 특히 B2B AI 서비스라면 "우리 서비스가 다른 모델 학습에 악용될 수 있는가"를 먼저 봐야 한다.
좋은 점
- AI 모델 distillation 문제가 숫자와 사례로 드러났다.
- 모델 보안이 단순 해킹 방어가 아니라 API 운영 문제라는 점을 보여준다.
- AI 기업과 정부 규제의 연결이 더 선명해졌다.
아쉬운 점
- Alibaba 측의 반론이나 공식 입장은 아직 충분히 확인되지 않았다.
- 핵심 근거가 Anthropic의 서한과 주요 매체 보도라, 세부 기술 증거는 외부에서 검증하기 어렵다.
- 실제로 Qwen 모델 훈련에 어느 정도 영향을 줬는지는 아직 확인 필요다.
내 생각
이번 뉴스는 꽤 현실적인 AI 보안 이슈다. 모델이 좋아질수록 "모델을 훔친다"는 말의 의미가 바뀐다. 예전에는 가중치 파일이나 코드 유출을 떠올렸다면, 이제는 출력값을 대량으로 받아 다른 모델을 따라 학습시키는 방식이 문제가 된다.
물론 Anthropic의 주장만으로 모든 사실관계를 확정할 수는 없다. Alibaba 쪽 설명이 아직 부족하고, 서한에 담긴 기술적 증거를 외부에서 직접 검증하기도 어렵다. 그래서 제목은 강하게 잡되, 본문에서는 "의혹"과 "주장"의 선을 분명히 그어야 한다.
그럼에도 흐름은 분명하다. 앞으로 frontier AI 경쟁은 모델 성능표만 보는 게임이 아니다. 누가 더 안전하게 접근을 관리하고, 대량 추출을 막고, 정부와 규제기관을 설득하느냐가 경쟁력이 될 수 있다.

결론
Anthropic의 Alibaba 관련 주장은 AI 모델 경쟁의 다음 쟁점을 잘 보여준다. 이제는 모델을 잘 만드는 것만큼, 모델 출력이 어떻게 쓰이고 어디까지 접근을 허용할지 정하는 일이 중요해졌다.
아직 Alibaba 측의 충분한 반론과 독립 검증은 필요하다. 하지만 2,880만 건의 교환과 약 2만5,000개 계정이라는 숫자만으로도, AI 서비스 운영자들이 그냥 넘길 사안은 아니다.
한 줄 평: "AI 모델 경쟁은 이제 성능표 밖, 접근 통제와 출력 보안으로 번지고 있다."
여러분은 모델 출력으로 다른 AI를 학습시키는 걸 어디까지 허용해야 한다고 보시나요?
참고 출처
- Anthropic letter to U.S. Senate Banking Committee - Illicit access to American AI models by Alibaba-affiliated operators
- Anthropic - Detecting and preventing distillation attacks
- Taipei Times / Reuters - Anthropic says Alibaba illicitly pulled from Claude
- Wall Street Journal - Anthropic Claims Alibaba Ran 'Brazen' Campaign to Access Its Claude AI Model
- Business Insider - Anthropic is accusing China's Alibaba of exploiting its AI models
- Financial Times - Anthropic accuses Alibaba of obtaining illicit access to Claude