OpenAI가 2026년 5월 4일 Engineering 블로그에 How OpenAI delivers low-latency voice AI at scale를 공개했다. 새 모델 발표라기보다 ChatGPT voice와 Realtime API WebRTC endpoint를 안정적으로 운영하기 위해 WebRTC media architecture를 어떻게 바꿨는지 설명한 글이다.
핵심은 단순하다. 음성 AI는 모델이 좋아도 첫 연결이 느리거나, packet loss와 jitter가 커지거나, barge-in 반응이 늦으면 바로 어색해진다. OpenAI는 이 문제를 모델 레이어가 아니라 relay + transceiver 구조의 네트워크/미디어 인프라 문제로 풀었다.
한눈에 보기
- 발표 내용: OpenAI가 저지연 음성 AI를 위한 WebRTC media architecture를 공개했다.
- 핵심 변화: one-port-per-session 방식의 한계를 줄이고, relay가 packet routing을 맡고 transceiver가 WebRTC session state를 유지하는 구조를 사용한다.
- 개발자 관전 포인트: Realtime API 기반 음성 에이전트 품질은 모델 호출뿐 아니라 ICE, DTLS, SRTP, UDP routing, region steering까지 같이 봐야 한다.
- 한 줄 결론: 음성 AI 경쟁은 이제 모델 성능표만으로 설명되지 않고, 실시간 미디어 인프라 품질까지 포함한다.
이번 글, 뭐가 중요한가
OpenAI는 이 글에서 ChatGPT voice, Realtime API WebRTC endpoint, 여러 research project가 같은 실시간 미디어 요구사항을 공유한다고 설명했다. 사용자는 대화가 말의 속도로 이어질 때 자연스럽다고 느낀다. 반대로 네트워크가 막히면 어색한 침묵, 끊긴 interruption, 늦은 barge-in으로 바로 체감된다.
OpenAI가 제시한 요구사항도 이 관점과 맞닿아 있다.
- 9억 명 이상 weekly active users를 감당할 global reach
- session 시작 직후 바로 말할 수 있는 빠른 connection setup
- turn-taking이 자연스럽게 느껴지는 낮고 안정적인 media round-trip time
- 낮은 jitter와 packet loss
이건 모델 API를 한 번 빠르게 호출하는 문제와 다르다. 음성은 연속 stream이다. 사용자가 말을 끝낼 때까지 기다렸다가 업로드하는 방식이 아니라, 말하는 중에도 transcription, reasoning, tool call, speech generation이 이어져야 한다. 그래서 WebRTC 같은 실시간 미디어 표준이 중요해진다.
기존 방식의 한계: one-port-per-session
OpenAI의 첫 구현은 Go와 Pion 기반의 단일 transceiver service였다. 이 서비스가 signaling과 media termination을 함께 처리했고, ChatGPT voice와 Realtime API WebRTC endpoint를 지원했다.
문제는 전통적인 WebRTC one-port-per-session 방식이 OpenAI 규모의 Kubernetes 환경과 잘 맞지 않았다는 점이다. session마다 public UDP port를 노출하면 고동시성 환경에서 매우 큰 UDP port range를 운영해야 한다.
이 방식은 세 가지 문제가 있다.
- cloud load balancer와 Kubernetes service가 수만 개의 public UDP port를 service 단위로 다루기 어렵다.
- 외부에서 접근 가능한 UDP surface가 커져 보안 정책과 audit이 복잡해진다.
- pod가 늘고 줄고 재스케줄링되는 환경에서 각 pod가 안정적인 port range를 예약하고 광고해야 하므로 autoscaling과 맞지 않는다.
OpenAI가 세운 목표는 좁고 고정된 UDP surface만 public internet에 노출하면서도, 각 packet을 해당 WebRTC session을 소유한 transceiver로 안정적으로 보내는 것이었다.
OpenAI의 선택: relay + transceiver
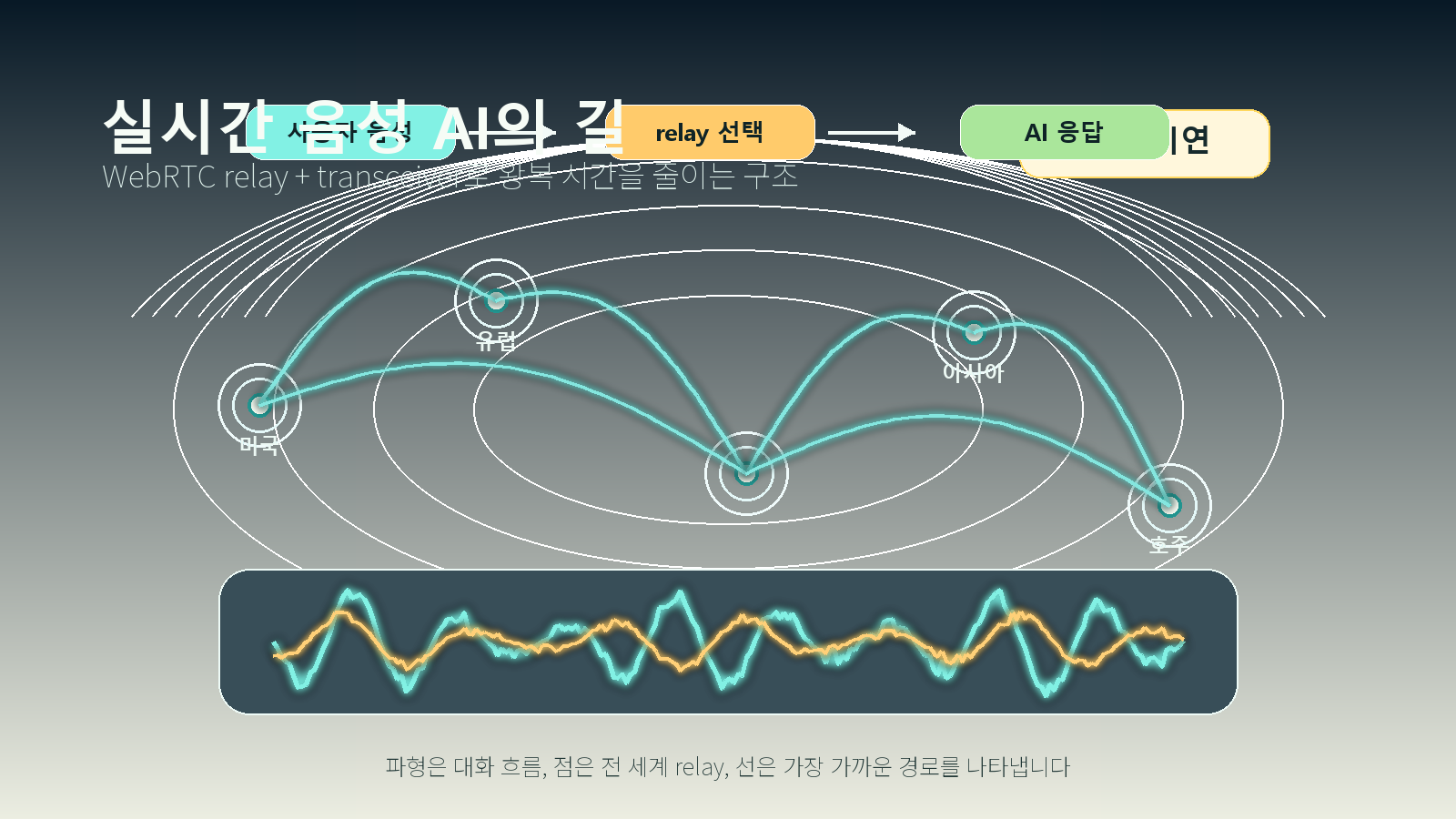
OpenAI가 공개한 구조는 packet routing과 protocol termination을 분리한다.
relay는 public internet 쪽에 노출되는 가벼운 UDP forwarding layer다. media를 decrypt하지 않고, ICE state machine을 돌리지 않으며, codec negotiation에도 참여하지 않는다. packet metadata를 필요한 만큼만 읽고, 해당 session을 소유한 transceiver로 packet을 넘긴다.
transceiver는 stateful WebRTC endpoint다. ICE connectivity check, DTLS handshake, SRTP encryption key, session lifecycle을 소유한다. client 입장에서는 표준 WebRTC flow가 유지된다. 바뀐 것은 client protocol이 아니라 OpenAI 내부에서 packet이 이동하는 방식이다.
이 선택이 중요한 이유는 backend service들이 WebRTC peer처럼 행동할 필요가 줄어든다는 점이다. WebRTC의 어려운 session state는 transceiver에 남겨두고, inference, transcription, speech generation, tool use, orchestration은 더 일반적인 backend service처럼 scale할 수 있다.
first-packet routing이 핵심이다
이 구조에서 가장 까다로운 부분은 첫 packet을 어디로 보낼지 결정하는 일이다. relay는 packet path 위에서 첫 packet을 받지만, 아직 relay 내부에는 session state가 없다. 매번 외부 lookup service에 의존하면 hot path latency가 늘어난다.
OpenAI는 WebRTC가 이미 가진 ICE username fragment, 즉 ufrag를 routing hook으로 썼다. signaling 단계에서 transceiver가 session state를 만들고 SDP answer에 shared relay VIP와 UDP port를 돌려준다. client는 이 안정적인 목적지로 첫 media-path packet을 보낸다. 보통 이 첫 packet은 ICE connectivity 확인을 위한 STUN binding request다.
relay는 그 STUN packet에서 server-side ufrag를 읽고, 그 안의 routing hint를 decode해 destination cluster와 owning transceiver를 추론한다. 이후 DTLS, RTP, RTCP packet은 이미 만들어진 relay session state를 따라 흐르므로 매번 ufrag를 다시 decode할 필요가 없다.
relay state는 의도적으로 작다. in-memory forwarding state, monitoring counter, cleanup timer 정도만 가진다. relay가 재시작되어 state를 잃어도 다음 STUN packet에서 다시 route를 만들 수 있다. OpenAI는 route 회복을 더 빠르게 하기 위해 Redis cache도 사용한다고 설명했다.
global relay와 geo-steered signaling
OpenAI는 이 relay pattern을 global relay로 확장했다. 여러 지역에 relay ingress point를 두고, packet이 사용자의 지리적/네트워크 위치와 가까운 곳에서 OpenAI network로 들어오게 하는 방식이다.
signaling은 Cloudflare geo and proximity steering을 사용해 가까운 transceiver cluster로 보낸다. SDP answer는 Global Relay address를 제공하고, ufrag에는 Global Relay가 지정된 cluster로 media를 보낼 수 있는 routing information이 들어간다.
결과적으로 setup과 media 모두 가까운 entry path를 사용하면서도, session은 하나의 transceiver에 anchored된다. 음성 AI에서는 이 차이가 작지 않다. 사용자가 말을 시작하기까지 기다리는 시간, interruption 반응, turn-taking 감각으로 바로 이어지기 때문이다.
Go relay 구현 포인트
OpenAI는 relay service를 Go로 작성했고, 구현 범위를 좁게 유지했다. kernel-bypass framework까지 가지 않고 Linux networking stack과 Go에서 가능한 최적화를 조합했다.
공개된 구현 포인트는 다음과 같다.
- protocol termination 없음: relay는 STUN header와
ufrag만 최소한으로 읽고, 이후 packet은 opaque하게 forwarding한다. - ephemeral state: client address와 transceiver destination mapping을 짧은 timeout의 in-memory map으로 관리한다.
- horizontal scalability: 여러 relay instance가 load balancer 뒤에서 병렬로 동작한다.
SO_REUSEPORT: 같은 UDP port에 여러 relay worker가 bind해 단일 read loop 병목을 줄인다.runtime.LockOSThread: UDP-reading goroutine을 특정 OS thread에 고정해 cache locality와 context switching 측면에서 유리하게 만든다.- pre-allocated buffer와 minimal copying: Go garbage collection 부담을 줄인다.
중요한 점은 복잡성을 얇은 routing layer에 모았다는 것이다. client에 custom behavior를 요구하지 않고, backend service마다 WebRTC 복잡성을 전파하지 않는 쪽을 택했다.
실제 의미
사용자 관점에서는 "음성이 자연스럽다"는 감각이 더 중요해진다. 모델이 말은 잘해도 연결 시작이 늦거나, 말을 끊고 들어가는 반응이 늦거나, 중간에 음성이 흔들리면 제품 품질은 낮게 느껴진다.
개발자 관점에서는 Realtime API 기반 음성 에이전트를 만들 때 모델 선택만으로는 충분하지 않다는 신호다. media path, NAT traversal, packet loss, region routing, session ownership을 같이 봐야 한다. 특히 production에서는 "데모에서는 잘 됐는데 실제 사용자 환경에서 불안정한" 문제가 이 레이어에서 자주 생긴다.
비즈니스 관점에서는 음성 AI 제품의 품질 기준이 더 까다로워진다. call center, meeting assistant, tutor, sales assistant, coding agent voice interface 같은 제품은 latency와 interruption 처리에서 신뢰가 갈린다. 음성 AI가 실제 업무 흐름에 들어갈수록 이런 infrastructure detail이 제품 경쟁력이 된다.
주의할 점
이번 글은 architecture 설명이지, Realtime API의 새 성능 benchmark 표가 아니다. OpenAI가 latency, jitter, packet loss를 줄이기 위한 설계를 설명했지만, 세부 수치나 지역별 benchmark를 모두 공개한 것은 아니다.
또 실제 구현을 하려면 OpenAI Engineering 글만으로 끝내면 안 된다. Realtime API WebRTC endpoint의 현재 API 사양, authentication, SDP exchange 방식, rate limit, pricing은 공식 개발자 문서에서 별도로 확인해야 한다.
이 글은 모델 리뷰도 아니다. GPT Realtime 계열 모델의 음성 품질을 평가하는 글이 아니라, 그 모델과 제품을 안정적으로 연결하기 위한 미디어 인프라 이슈로 보는 것이 맞다.
결론
OpenAI의 이번 공개에서 중요한 메시지는 "음성 AI는 모델만의 문제가 아니다"라는 점이다. 자연스러운 대화 경험은 inference latency뿐 아니라 connection setup, media round-trip time, jitter, packet loss, routing, session ownership이 함께 맞아야 나온다.
OpenAI는 WebRTC 표준 client behavior는 유지하면서, 내부에서는 relay + transceiver 구조로 Kubernetes와 global routing에 맞는 형태를 만들었다. 앞으로 음성 AI 제품을 평가할 때는 어떤 모델을 쓰는지만 볼 게 아니라, 그 모델이 어떤 실시간 미디어 인프라 위에서 동작하는지도 같이 봐야 한다.
출처
- OpenAI Engineering,
How OpenAI delivers low-latency voice AI at scale, 2026년 5월 4일, Yi Zhang and William McDonald: https://openai.com/index/delivering-low-latency-voice-ai-at-scale/